2013年最初のブログは、処理能力と処理コストのトレードオフについてというちょっと真面目な話。RubyでIPアドレスから国名を引くという処理モジュールを書いた。
お正月にやってみたよ
事前に与えられる国/IPアドレスの対応データの定義
国名を引くための国/IPアドレスデータの定義であるが、
- フィールド1: IPアドレスの開始番号
- フィールド2: 割り当て数
- フィールド3: 国名
の3-タプルになっている。
フィールド1は、IPv4の整数値とする。192.168.1.0なら
(192*(2^24)) + (168*(2^16)) + (1 * 256) + 0= 3232235776
となる。
フィールド2は、そのIPアドレスからスタートして割り当てられている数を示す。たとえば/24であれば256である。192.168.1.0から256個のIPアドレスを割り当てられているなら192.168.1.0から192.168.1.255までが割り当てられているIPアドレスの範囲になる。
フィールド3は、ccTLD(二文字で国を表している文字列)である。日本だとJP、イギリスだとUKなどである。
1つのタプルは4-4-2 byteの合計10バイトで表されており、このタプルを1レコードとして約10万レコードがフィールド1のキーとして昇順に並んでいる。これ自体は事前に処理を行ってベースとなるデータレコードが作られて提供されているとする。
N個のタプルがあるとすると[a0,b0,c0][a1,b2,c3]…[aN-1,bN-1,cN-1] (ただしa0< a1 < …< aN-1)という並びになる。
入力と検索
入力は実際は192.168.0.3といった入力になるのだが、内部的には符号無し32ビット整数としているのでiとしよう。探すのは a0< = i < a0+b0 の条件にあうタプルに入っているc0である。
シーケンシャルサーチをすると平均ヒット確率が50%を越えるためにはNレコードであればN/2 に 1を加えた所まで探していかなければならない。10万レコードをもっているような場合は処理効率が悪すぎる、というのは考えるまでもない。
フィールド1のキー昇順の並びなのでバイナリーサーチが定番である。先頭と最後尾の中間にあるレコードを使い、その値より小さいか大きいかを判断する。入っている範囲の中で同じことを繰り返す。半分づつに絞れていき、最後までいくと2つのレコードが残る。レコード数がnの場合 (log(n)/log(2)) + 1 回より少ない探す回数で見つけることができる。100万レコードの中から探しても25回で探せることになる。50万回探すのと25回を探す差は圧倒的である。
実装をプラクティカルに考える
プログラム実装を考えるといくつかの方法が考えられる。
- 1) N個のレコードをファイルから最初から読み込んで、配列を作りそれから探す。(ここでは初期化方式と呼ぶ)
- 2) N個のレコードのファイルを読み込まず、必要なデータだけを読み込む。(ここではデマンド方式と呼ぶ)
1の初期化方式は初期化プロセスとしてデータファイルをすべて読み込み、個々のレコードを配列に格納し、しかる後に検索処理を始める。例題的なアプローチだが、初期化プロセスの時間はデータが増えれば増えるほど単調に増加する。1回の検索をするのにでも10万レコードを読み込むということが必要になる。
2は10万レコードを読み込まず、必要な量だけデータファイルをアクセスする。これは10万レコードをもったファイルをmmapすると簡単にできる。mmapはファイルをメモリのように扱えるメカニズムで使い方は簡単だ。ただしこれにはmmapのためのrubyのライブラリを使う必要がある。素のrubyで実装する場合、ファイルをシークする形で必要な分だけ読み取るというアプローチがある。答えを先にいってしまうが、mmapで実装してもファイルをシークする方式にしても大きな処理時間の差は出ないことがわかった(rubyのsimple-mmapを使用)。
さて2のデマンド方式であるが、まずレコード分の配列を作り、内容を入れずに、そのまま検索に利用する。検索時に配列をアクセスするわけだが、その時に該当の場所に内容がなければ、ファイルを該当の場所までシークして、データを読み込み、それを配列の該当部分に入れる。つまり配列はキャッシュとなる。
当然ながらファイルをシークするというコストがかかる。シークする回数が少なければ問題はないが、当然ながら、その回数が増えればコストがあがっていく。
実際はどうなのか
もし初期化に使うレコード数が100や200程度であれば1のアプローチで大きな処理時間の差は出ないだろう。(ただし、100や200のレコードでもリニアサーチとバイナリサーチとではレコードが100や200でも大きく違う)。だが10万レコードを事前に読み込むのである。確実に遅い。一方で先ほど書いたように検索数が多くなれば多くなるの程、何度もシークを繰り返す実装より、最初に読み込んだ方が早くなる。
これはもう実際にどう違うか試してみるしかない。
試してみた
架空のランダムなIPアドレスでは現実の動きとは違うので、自分の個人サイトh2np.netのウェブのアクセスログを2011年一年分を使って試してみると次のグラフのようになった。bsがバイナリーサーチ+初期化、bs-caがバイナリーサーチ+キャッシュである。このグラフはx軸の増加が2のn乗になっているので最期が急激に上がっているようにみえるが、実際は緩やかにかつ単調に増えている。
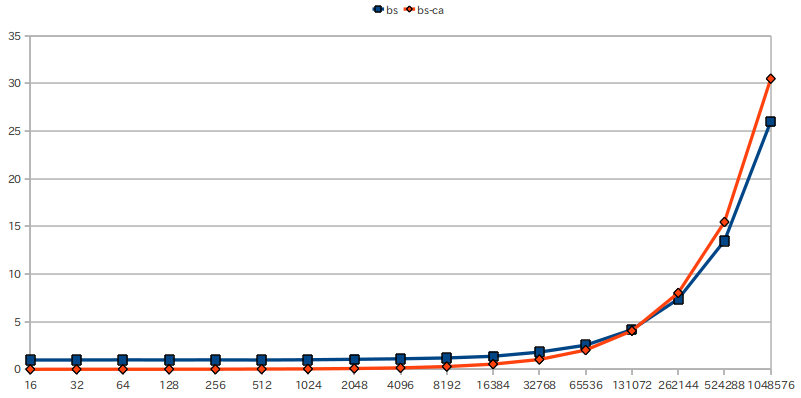
グラフ1: 初期化方式とデマンド方式の処理効率の違い
約13万件の検索あたりで同じ時間になる。だがその前は初期化する方が負けている。では13万件以下の検索数ではどうだろうかみてみる。
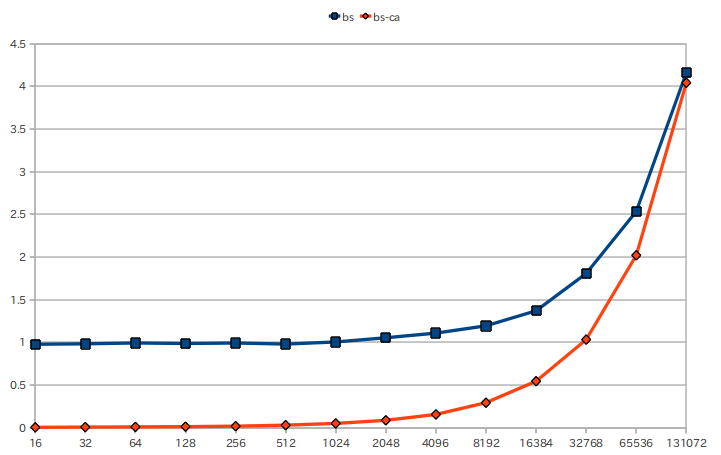
グラフ2: 初期化方式とデマンド方式の違い。検索数が少ない場合。
このグラフでわかるように、デマンド方式だと1024回程度であれば瞬時に終わる。6万回程度までならデマンド方式の方が明らかに有利である。
結論
初期化方式、デマンド方式にはそれぞれトレードオフがあり、初期化方式は立ち上がりはおそいが、そのかわり大量の検索を扱う時には有利、デマンド方式は立ち上がりが早く、ある程度の検索数までは有利である。ただし、その両者がどの程度の処理をおこなった時点で、有利になるか不利になるのかの、いわゆる損益分岐点みたいなものを探すのには実装がかかわってくるので実際に計測してみるしかない。
どんな時も万能の実装など、そうそうないのである。